4.2.6 파라미터 설정
- '3.5.2 Llama 3.1 학습 파라미터 설정' 참고
https://31weeks.tistory.com/483
[Day10] 한 권으로 LLM 온라인 스터디 1기 - 다중 GPU Llama3 파인튜닝
3.5 다중 GPU를 활용한 Llama3.1-8B-instruct 파인 튜닝 3.5.1 런팟 환경 설정H100XM x 41Pytorch 2.2.0Container Disk 400GBVolume Disk 400GBgit clone https://github.com/wikibook/llm-finetuningcd llm-finetuning/chapter3/3.5pip install -r requirem
31weeks.com
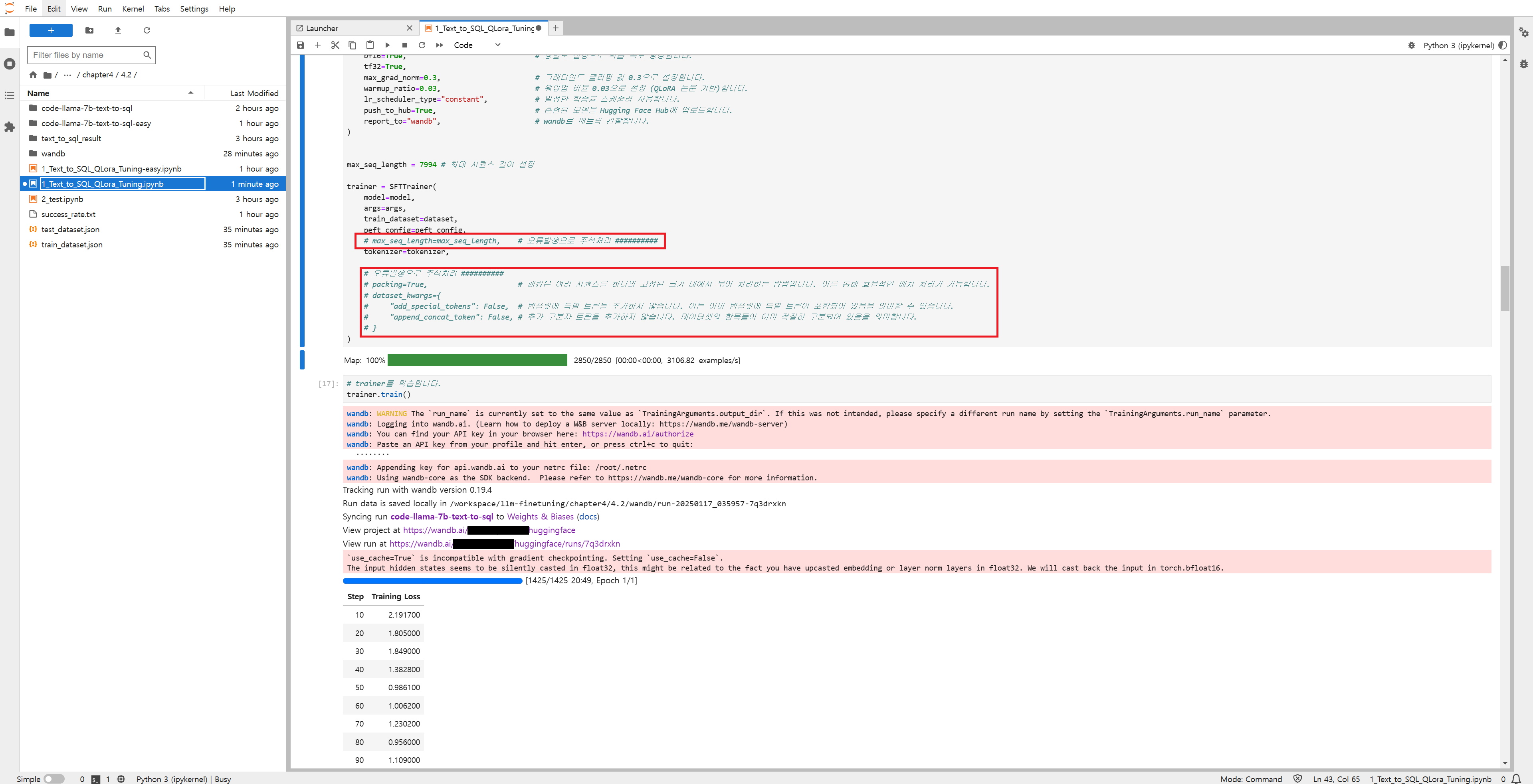
4.2.7 모델 학습
- model : Ko-Llama3 모델 지정
- args : 앞서 정의한 학습 관련 설정 포함
- train_dataset : 학습에 사용할 데이터셋 지정
- peft_config : 파라미터 효율적 파인튜닝(PEFT) 설정을 포함
- max_seq_length : 모델이 처리할 수 있는 최대 시퀀스 길이 설정
- tokenizer : 텍스트를 토큰화 하는 데 사용할 토크나이저 지정
- packing : True로 설정해 데이터 패킹을 활성화 → 메모리 사용 최적화
- dataset_kwargs : 데이터셋 처리 관련 추가 설정포함(특수 토큰을 추가하지 않고 연결 토큰도 추가하지 않도록 설정)
4.2.8 허깅페이스 업로드
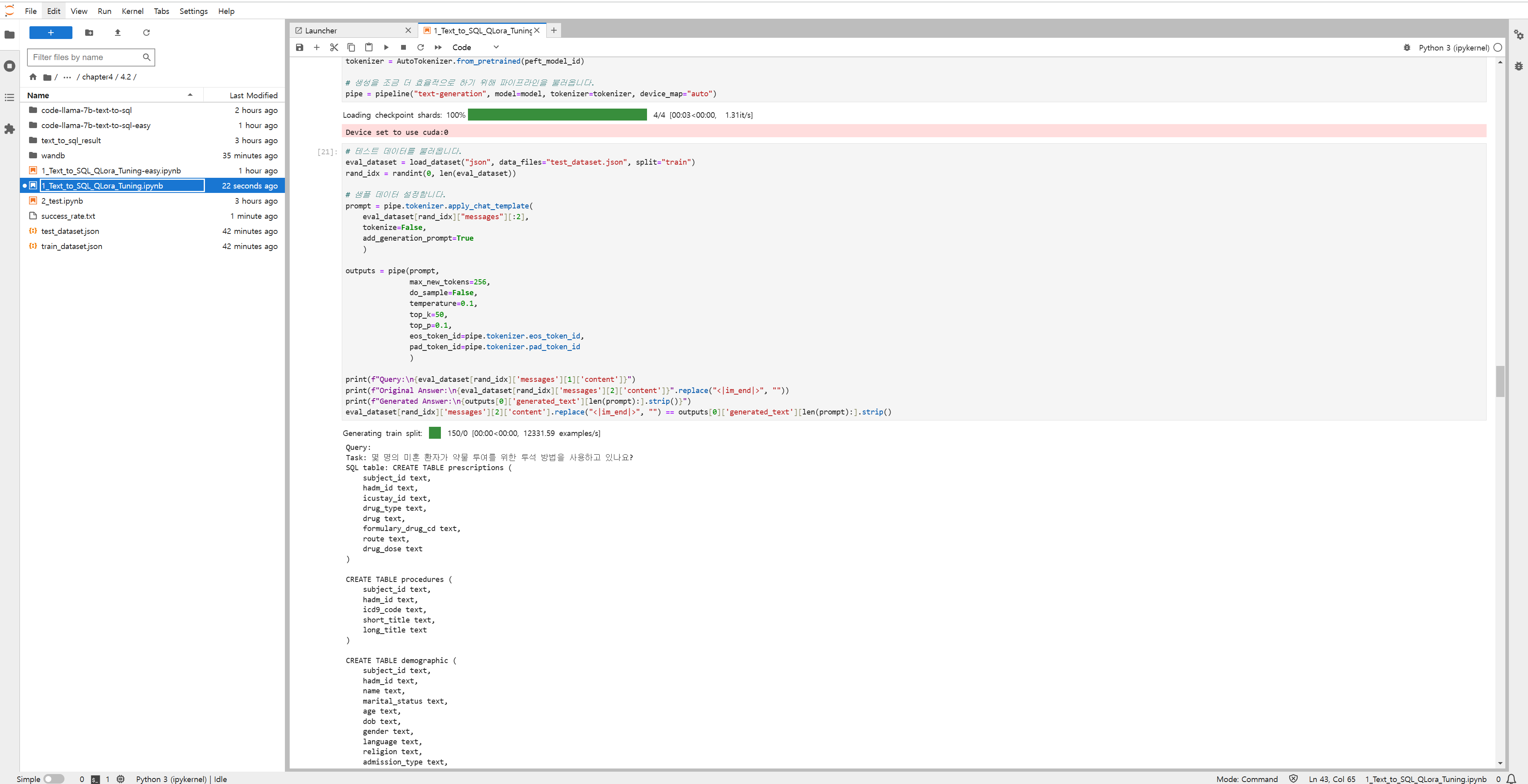
4.2.9 학습한 모델 테스트
- 모델 경로 지정 : 학습한 모델의 저장 위치를 peft_model_id 변수에 지정
- 모델 로딩 : AutoPeftModelForCausalLM 클래스를 사용해 PEFT 어댑터가 적용된 사전 학습 모델을 불러옴
- device_map="auto" : 모델을 불러올 떄 자동으로 적절한 장치(CPU or GPU)에 할당
- torch.bfloat16 : 모델을 bfloat16 형식으로 로드 → 메모리 사용 최적화 - 토크나이저 로딩 : AutoTokenizer 클래스를 사용해서 모델에 맞는 토크나이저를 볼러옴
- 파이프라인 설정 : 허깅페이스에서 제공하는 pipeline 함수를 사용해서 텍스트 생성 파이프라인을 설정함
- text-generation : 텍스트 생성 작업을 수행하도록 지정
- model=model : 앞서 로드한 모델을 사용
- tokenizer=tokenizer : 앞서 로드한 토크나이저 사용
- device_map=auto : 자동으로 적절한 장치(CPU or GPU)에 할당
4.2.10 Exact Match를 활용한 평가
- 특수 토큰 제거 : 모든 답병에서 eos_token이라 불리는 <|im_end|>라는 특수 토큰 제거
- 이 토큰은 모델이 텍스트 생성을 끝냈다는 것을 나타내는 표시이지만, 실제 내용비교에는 불필요 - 답변 비교 : success_rate 리스트에 저장된 각 항목에 대한 모델이생성한 답변과 특수 토큰이 제거된 실제 정답을비교
- 결과 저장 : 비교 결과는 generated_result라는 새로운 리스트에 저장됨(True or False로 구성)
- 성능 평가 : generated_result 리스트에서 True 개수가 많을수록 모데르이 성능이 좋다고 판단할 수 있음

4.2.11 OpenAI API로 평가하기
- 중복 처리 방지 : pathlib의 path를 사용해서 이미 처리된 파일이 있다면 건너뛰어 불필요한 중복 작업 방지
- JSON 형식의 응답 : GPT-4o-mini 모델에 요청할 때 response_format을 JSON 객체로 지정
- 결과 처리의 일관성이 높아지고 후속 처리가 더 쉬워짐 - 병렬 처리 구현 : pqdm 라이브러리를 사용해 병렬처리 구현, n_jobs=40으로 설정해서 40개 작업 동시에 실행
- 결과 데이터 변환 : results 리스트에 저장된 각 결과를 JSON 형식으로 파싱, 이 과정에서 문자열 형태의 JSON 데이터를 파이썬 객체로 변환해 json_result 리스트에 추가 → 결과 데이터를 쉽게 분석할 수 있는 형태로 만듬
- 데이터 프레임 생성 : pandas 라이브러리 사용해 데이터프레임으로 만듬 → 데이터 분석과 처리를 용이하게 해줌
- 데이터 타입 변환 : 데이터프레임의 answer 열은 문자열 형태의 '0' 또는 '1'일 수 있음 → 정확한 계산을 위해 정수형으로 변환(lambda 함수 사용)
- 정확도 계산 : 변환된 answer 열의 합계를 전체 데이터 수로 나누어 정확도 계산

* 배치 사이즈 영향
배치사이즈를 1에서 3으로 늘리면 학습 속도는 빨라지지만, 각 데이터에 대한 모델의 적응력이 떨어질 수 있음 → SQL 쿼리 생성과 같은 복잡한 작업에서는 작은 배치 사이즈가 더 유리할 수 있음
* 테스트셋 크기의 차이
1,500개의 랜덤 샘플과 13,000개의 전체 테스트셋은 규모 차이가 크다. 더 큰 테스트셋에는 다양한 난이도의 문제가 포함돼어있어 성능이 낮아질 수 있음
* 랜덤 샘플의 영향
1,500개 샘플에 상대적으로 쉬운 문제들이 선택됐을 가능성 있음
* 과적합 가능성
배치 사이즈 1로 학습한모델이 훈련 데이터에 과적합되어 작은 테스트셋에서는 높은 성능을 보이지만, 큰 테스트셋에서는 성능이 떨어질 수 있음
* 학습의 안정성
큰 배치 사이즈가 더 안정적일 수 있지만, 복잡한 태스크에서는 작은 배치 사이즈가 더 섬세한 학습을 가능하게 할 수 있음
'프로그래밍 > LLM' 카테고리의 다른 글
| [Day 0] LLM & RAG 실전 챌린지 - 준비 (0) | 2025.09.07 |
|---|---|
| [Day15] 한 권으로 LLM 온라인 스터디 1기 - vLLM 서빙 (1) | 2025.01.26 |
| [Day13] 한 권으로 LLM 온라인 스터디 1기 - 효율적인 파라미터 튜닝 (양자화 & QLoRA) (0) | 2025.01.26 |
| [Day12] 한 권으로 LLM 온라인 스터디 1기 - 효율적인 파라미터 튜닝 (LoRA 2) (0) | 2025.01.26 |
| [Day11] 한 권으로 LLM 온라인 스터디 1기 - 효율적인 파라미터 튜닝 (LoRA 1) (0) | 2025.01.26 |