728x90
반응형
3.2 Gemma와 Llama3 모델 구조 분석
3.2.1 Gemma 모델 구조 분석
- 매개변수(7B, 13B, 34B, 72B 등)의 수를 늘려서 성능을 높이는데 집중했던 재부분의 모델들과는 반대로 모델의 크기를 크게 줄여서 고성능 컴퓨팅 자원이 부족한 환경에서도 언어모델을 황용할 수 있게 하려는 혁신적인 시도
a. input_layernorm, post_attention_layernorm 추가 : 그레디언트를 적절한 크기로 유지 → 안정적 학습, 더 좋은 성능
b. RoPE(Rotary Position Embedding) 도입 : 각 토큰의 위치를 상대적인 각도로 표시
c. 활성화 함수 : ReLU의 한계를 극복하기 위해 GELU와 GLU를 결합한 GeGLU라는 새로운 활성화 함수를 사용

3.2.2 Gemma와 Gemma2 모델 비교
| 특징 | Gemma | Gemma2 |
| 어텐션유형 | 멀티헤드 어텐션 | 로컬 슬라이딩 윈도 및 글로벌 어텐션, 그룹 쿼리 어텐션 |
| 훈련 방식 | 다음 토큰 예측 | 지식 증류(2B, 9B), 다음 토큰 예측(27B) |
| 정규화 | RMSNorm | RMSNorm |
| 로짓 제한 | 없음 | 어텐션 및 최종 레이어의 로짓 제한 적용 |
| 모델 크기 | 2B, 7B 모델 | 2B, 9B, 27B 모델 |
3.2.3 Llama3 모델 구조 분석
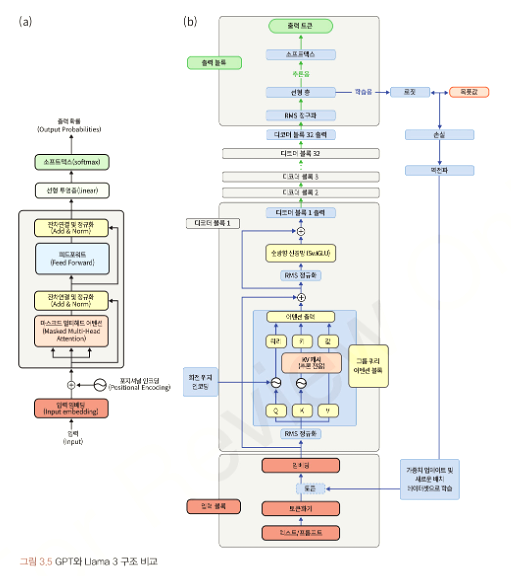
3.2.4 GPT, Gemma, Llama 비교
| 특징 | GPT | Gemma | Gemma2 | Llama3 |
| 아키텍처 | Decoder | Decoder | Decoder | Decoder |
| 위치 인코딩 | Sinusoidal PE |
RoPE | RoPE | RoPE |
| 정규화 | Layer Norm | RMS Norm | RMS Norm | RMS Norm |
| 어텐션 메커니즘 | Multi-Head Attention |
Multi-Head Attention |
Local Sliding Window and Global Attention Grouped-Query Attention |
Grouped Multi-Query Attention |
| 활성화 | ReLU | GEGLU | GEGLU | SwiGLU |
| 데이터 크기 | 4.5M + 36M | ~ 6T | ~ 13T | 15T |
728x90
반응형
'프로그래밍 > LLM' 카테고리의 다른 글
| [Day7] 한 권으로 LLM 온라인 스터디 1기 - 단일 GPU Gemma 파인튜닝 1 (0) | 2025.01.25 |
|---|---|
| [Day6] 한 권으로 LLM 온라인 스터디 1기 - GPU 병렬화 기법 (0) | 2025.01.25 |
| [Day4] 한 권으로 LLM 온라인 스터디 1기 - 파인튜닝 개념 (1) | 2025.01.25 |
| [Day3] 한 권으로 LLM 온라인 스터디 1기 - 멀티헤드 어텐션 & 피드포워드 (0) | 2025.01.25 |
| [Day2] 한 권으로 LLM 온라인 스터디 1기 - 언어 모델 구조 및 셀프 어텐션 메커니즘 이해 (0) | 2025.01.24 |